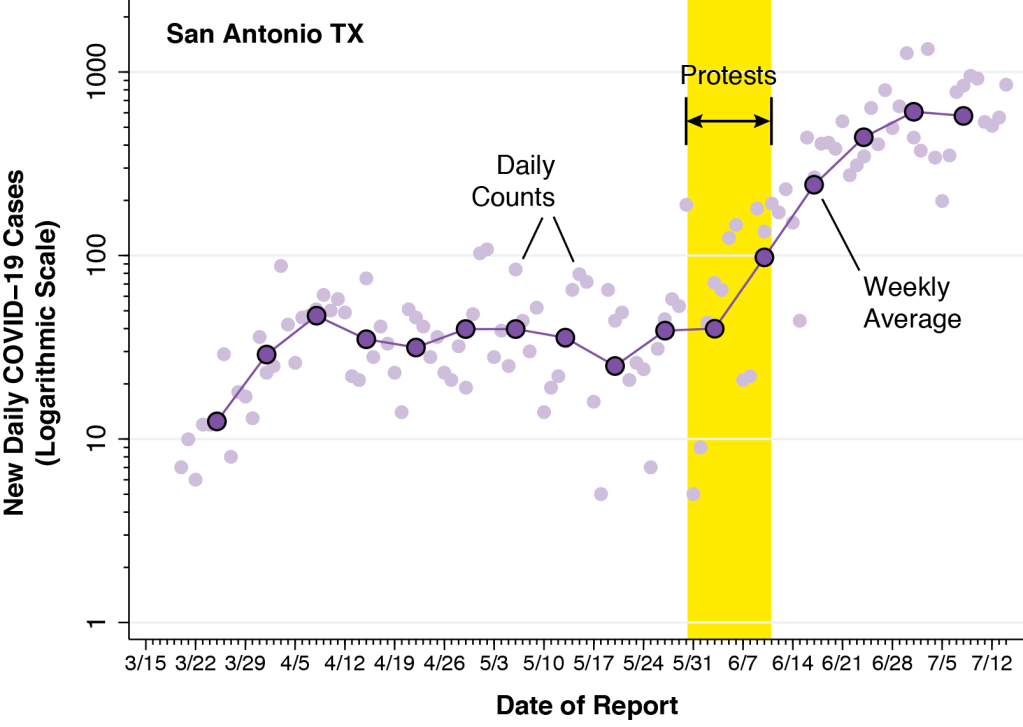
When herd immunity is achieved through large-scale population exposure, the epidemic doesn’t come to a halt. Millions more could ultimately be infected.
What, exactly, is herd immunity? Let’s look at some recent descriptions.
“Herd immunity occurs when enough people become immune to a disease to make its spread unlikely.” Herd immunity is “the point at which the virus can no longer spread widely because there are not enough vulnerable humans.” “Herd immunity occurs when a large portion of a community (the herd) becomes immune to a disease, making the spread of disease from person to person unlikely.”
Another authority has noted, “For example, if 80% of a population is immune to a virus, four out of every five people who encounter someone with the disease won’t get sick (and won’t spread the disease any further). In this way, the spread of infectious diseases is kept under control.”
And still another reference explains, “Herd immunity can be achieved when so many members of a population have become immune to an infectious disease that it can’t find new people to infect. There are two ways to get there: by exposing a large percentage of the population to a virus so they can develop antibodies on their own, or by vaccinating enough people to interrupt its transmission.”
The last description does draw an important distinction between herd immunity acquired through large-scale population exposure and herd immunity acquired through a campaign of immunization. But it does not go far enough. That’s because the two ways of achieving herd immunity have vastly different consequences. In fact, the widespread tendency to confuse the two has led to a major misconception as to what would happen the day after enough people got infected to cross the herd immunity threshold.
Herd Immunity Through Large-Scale Population Exposure
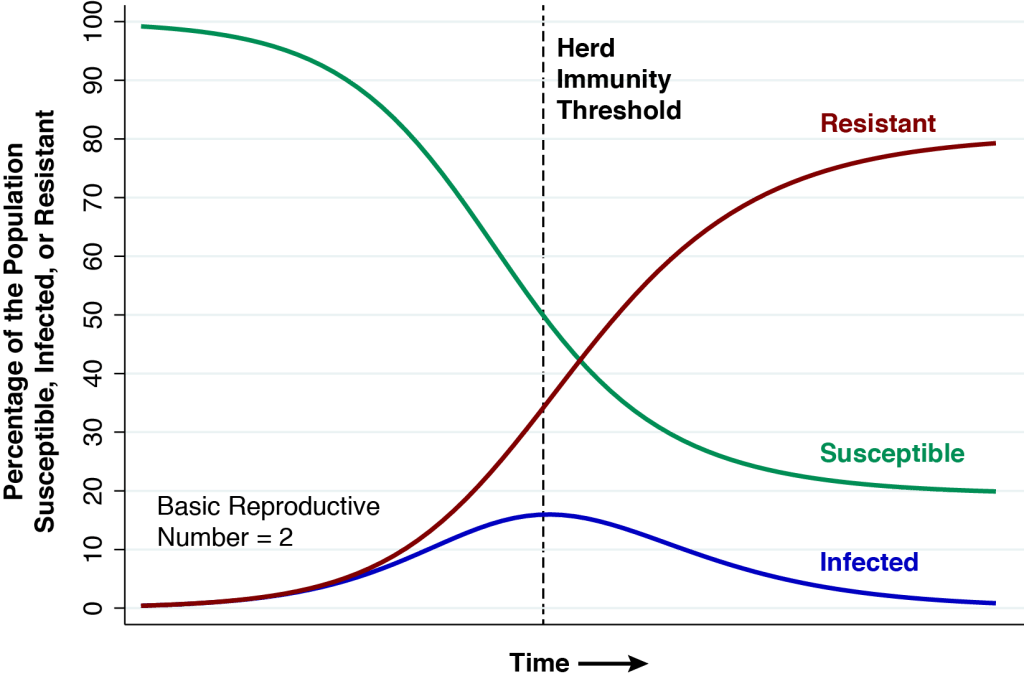
The above graphic shows the natural course of an epidemic governed by the classic SIR model, first described in 1927, which has served as the mainstay of mathematical epidemiology for nearly a century. This particular realization of the model has three features. First, the entire population is assumed to be naïve to the infectious agent at the outset. Nobody has natural immunity. Second, the epidemic is seeded by a very small number of infectious individuals imported from outside the population. Third, the basic reproductive number (or 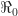
At the start of the epidemic at the very left, the green curve shows that nearly 100 percent of the population is susceptible (S) to the infectious agent. The blue curve seems to show that no one is initially infected (I), but in fact the proportion seeding the epidemic is so small that we can’t see it on the graph. The red curve shows that zero percent of the population is initially resistant (R).
As the epidemic gets going, the proportion of infected people initially grows. But each infected individual remains infectious only for a limited time period. He or she eventually becomes resistant, either by recovering from the infection or dying. As more people get infected, the proportion remaining susceptible falls, and as more infected people recover from their infections, the proportion becoming resistant rises. At all times during the course of the epidemic charted in the graphic, the sums of the proportions susceptible, infected, and resistant add to 100 percent.
The Herd Immunity Threshold
In the classic epidemic model we’ve charted above, the herd immunity threshold is reached when the proportion of infected people reaches a peak. At this point, exactly half of the population remains susceptible. In mathematical terms, the remaining proportion of susceptible individuals at the point of herd immunity is the inverse of the basic reproductive number, that is, 
At the start of the epidemic, each infected person was passing his or her infection to two other people. But with half of the population no longer susceptible, that won’t happen any longer. Infected person A will expose the infectious agent to individuals B and C. But the infection won’t take in the case of person C, who is either infected or resistant, and thus can’t acquire a new infection. Thus, each infected person (individual A) will be replaced by only one other infected person (individual B). The rate of growth of the infected population is exactly zero.
As the epidemic passes the immunity threshold, so that the proportion of susceptible persons falls below 50 percent, the rate of growth of the infected population turns negative. One infected person will give rise on average to less than one other infected person, and the proportion infected declines. That’s exactly what we see happening in the blue curve in the graphic.
The Catch
But there’s a problem, a catch, a rub. At the threshold of herd immunity, the red curve tells us that only 35 percent of the population is actually resistant, while the blue curve tells us that 15 percent are still infected. Each remaining infected person will indeed cause less than one new infection, and the percentage infected will indeed begin to fall. But there are still plenty of infected people to continue to pass their infections to the remaining susceptible individuals. In fact, at the far right of the graphic, by the time the epidemic finally fades away, the red curve tells us that about 80 percent of the population will have either recovered or died.
Millions More
Perhaps percentages are too abstract, too intangible. Here’s an application with absolute numbers. We start out with a population of 300 million susceptible people. We reach herd immunity when only 150 million remain susceptible. At that point, 45 million individuals will be actively infected and 105 million will have recovered or died. By the time the epidemic is over, however, 240 million will have either recovered or died. That is, 240 – 150 = 90 million additional people are infected after the herd immunity threshold is reached.
Why This Differs from Mass Immunization
Think about how different the roll-out of the epidemic would be if 50 percent of the susceptible individuals were instead immunized at the outset. When each of a handful of infected individuals is imported from outside, he or she will be unable to infect more than one other person. While it could still take some time for the resulting infections to completely dissipate, the extent of propagation will be minuscule in comparison to the our previous scenario of herd immunity through large-scale population exposure.
Total Deaths Are Understated, Too.
More than a few commentators have rightly pointed out that lots of people will die by the time we get to herd immunity. The message of the present analysis is that these estimates of the numbers of deaths are also understated.
For the sake of argument, let’s assume an infection fatality rate of 0.5 percent, which is at the low end of the World Health Organization’s recent estimate. Our SIR model teaches us that at the point of herd immunity, 50 percent of the population will have been infected. That means 0.5% 
While all of the foregoing results have been known for nearly a century, we have been searching far and wide for someone to explicitly acknowledge them in the context of the current COVID-19 pandemic. We have so far found only one instance. Almost as an afterthought to an article that likewise omits the long tail of infections in its calculation of how many millions will have to die, the Washington Post aptly quotes Carl Bergstrom of the University of Washington: “The epidemic doesn’t stop on a dime when you hit herd immunity. … The herd immunity point is when you’re at the peak of the epidemic. So you’ve come up the curve. But you still got to go all the way back down.”
But Aren’t We Closer to Herd Immunity Than We Thought?
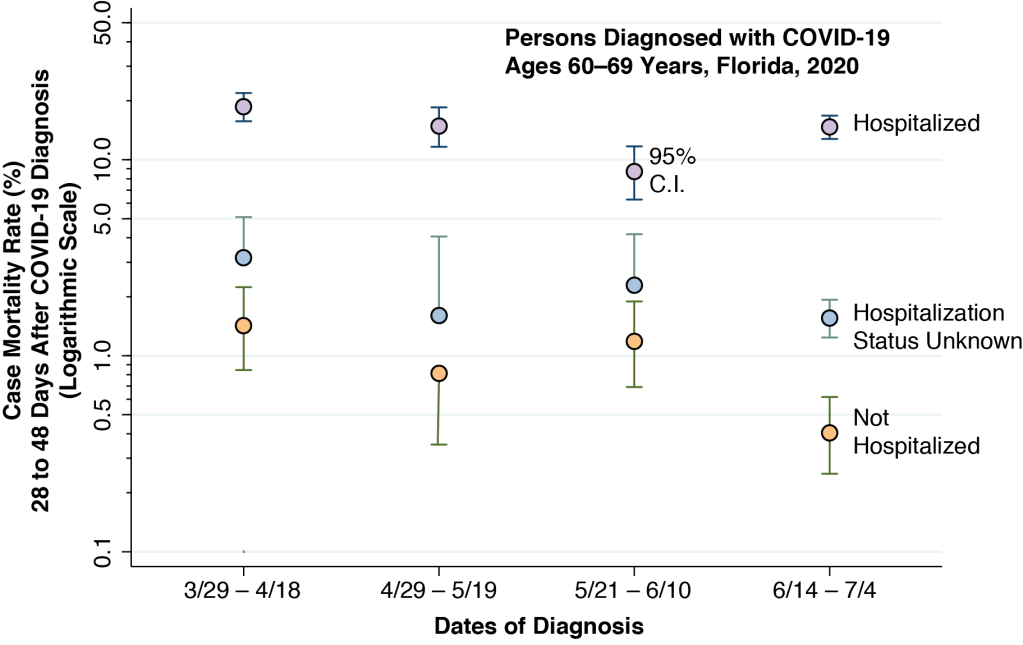
A number of analysts have suggested that we may be closer to herd immunity than we thought. One source of evidence is that some individuals may already have a degree of cross-immunity from other prevalent coronaviruses – though the data are too meager at this juncture to know how many. Another line of argument is based on the idea of incomplete mixing. The entire population could reach herd immunity, so the argument goes, once the groups with the most infectious individuals become saturated with infections. Data from Florida, however, indicate that there is plenty of mixing from the most infectious to the most susceptible populations.
Still, in terms of our classic SIR model, these contentions share a common feature – namely, the initial proportion of susceptible persons is less than 100 percent. That would indeed change the scale of our model, but not the basic dynamics.
Let’s start out once more with a population of 300 million people, but this time assume that 100 million are not susceptible from the get-go. For the remaining 200 million, we reach the herd immunity threshold when 100 million (or 50 percent of the initial susceptible individuals) have gotten infected. By the time the epidemic has full dissipated, 160 million (or 80 percent) will have been infected.
What If Our Estimate of the Basic Reproductive Number is Wrong?
We assumed that the basic reproductive number 
In our application of the classic SIR model, we further assumed that the population was closed. We could certainly complicate our model, allowing for new entrants and new exits, but the same overall dynamics would still apply. Of course, a country could encourage the immigration of millions of resistant individuals. But we don’t think that’s what anybody has in mind.
What About Social Distancing?
At this juncture, there is plenty of evidence that social distancing reduces viral transmission, and that the reversal of social distancing enhances transmission. One could imagine an endgame where social distancing measures are used to modulate the rate of infection until herd immunity is gradually achieved over the long run. That strategy would indeed mitigate the problem identified in this article.
But our objective here was not to recommend or predict how we will ultimately get out of this mess. Instead, our narrower goal was to bring to light the hidden costs of a strategy of letting lots of people get sick in the name of herd immunity.
Technical Notes
Classic SIR Model
We’ll work with the classic SIR model. It is the simplest mathematical model describing the time course of an epidemic. A more complicated model – of which there are a great many, including SEIR, SEIIR, and SEIAR – would do no more than distract attention from the main issue. Everything that follows here has been known for nearly 100 years.
Let 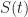


for all
The SIR model is governed by two coupled differential equations. The first equation is a law of mass action describing the rate at which susceptible individuals get infected. Specifically,
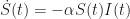
where 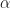

The second equation describes the rate at which infected individuals become resistant. Specifically,
where 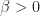

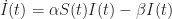
We start off our epidemic at time 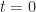
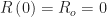
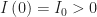
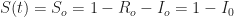
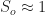
How Many Are Infected in the Long Run
In the long run, as time 

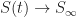



To derive an expression for these limiting quantities, we combine our two differential equations 




As time 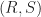
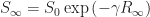

The root of this equation is thus the limiting quantity 
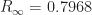

Reproductive Number and Herd Immunity Threshold
Let’s revisit the differential equation governing the growth in the proportion 

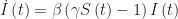

is the reproductive number of the epidemic at time 

When the reproductive number 

The Epidemic Does Not End at the Herd Immunity Threshold.
At the herd immunity threshold, where the growth rate of infected individuals is zero, there is still a positive number of infected individuals in the population, and they will continue to infect other susceptible persons.
Let’s further characterize the moment 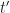
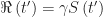


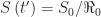
According, the combined number of infected and resistant individuals at the herd immunity threshold is 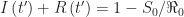
At the threshold of herd immunity, when 


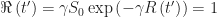
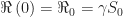




Accordingly, for an epidemic with 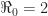
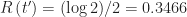
Comparing the Herd Immunity Threshold With the Long Run
We have assumed an SIR model where everyone is naive to the infectious agent and where the initial number of infected individuals is small, so that 

Proportions of Individuals in the Susceptible (S), Infected (I) and Resistant (R) States at the Herd Immunity Threshold and in the Long Run
| | |
 | 0.5000 | 0.2032 |
| 0.1534 | – |
 | 0.3466 | 0.7968 |













 denote that probability that any two randomly located patrons are within a distance
denote that probability that any two randomly located patrons are within a distance 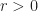 of each other. If a total of
of each other. If a total of 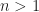 patrons are randomly located in the bar room, then the mean number of pairs of patrons within the infectious radius
patrons are randomly located in the bar room, then the mean number of pairs of patrons within the infectious radius  is
is  . For any given shaped bar room and any fixed infectious radius
. For any given shaped bar room and any fixed infectious radius  of patrons.
of patrons.