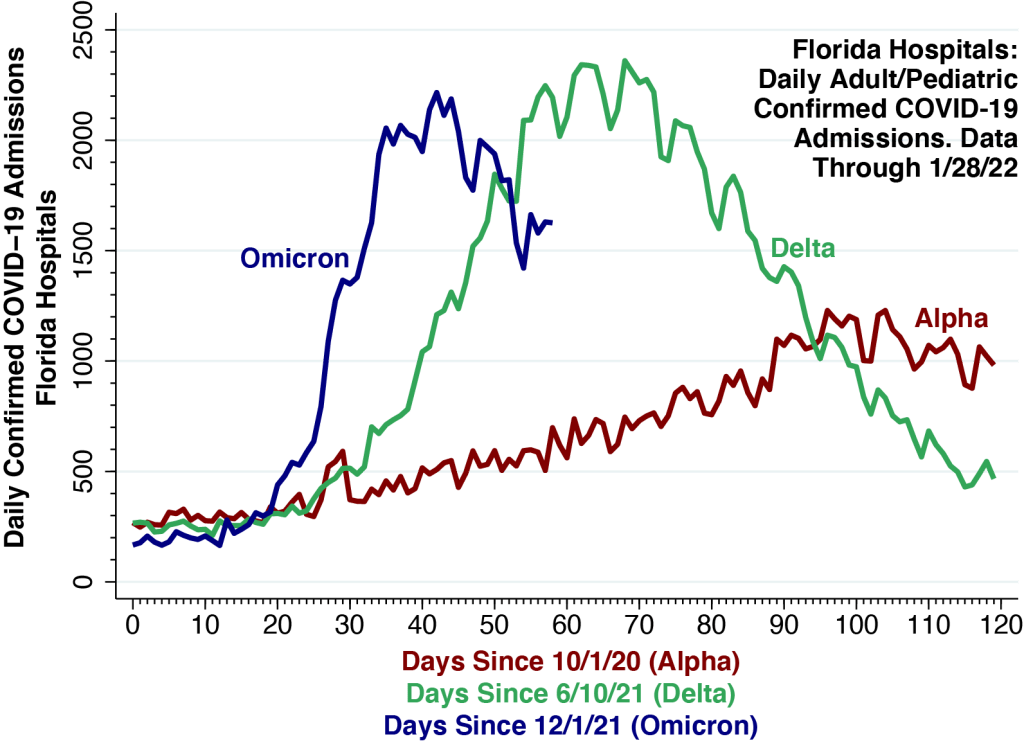
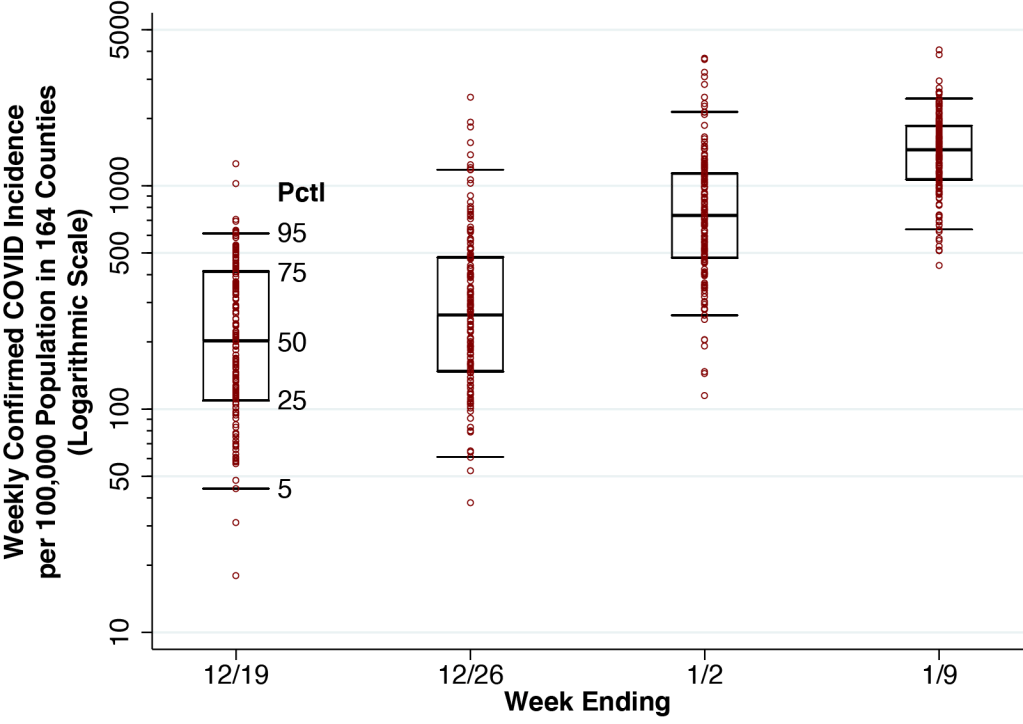
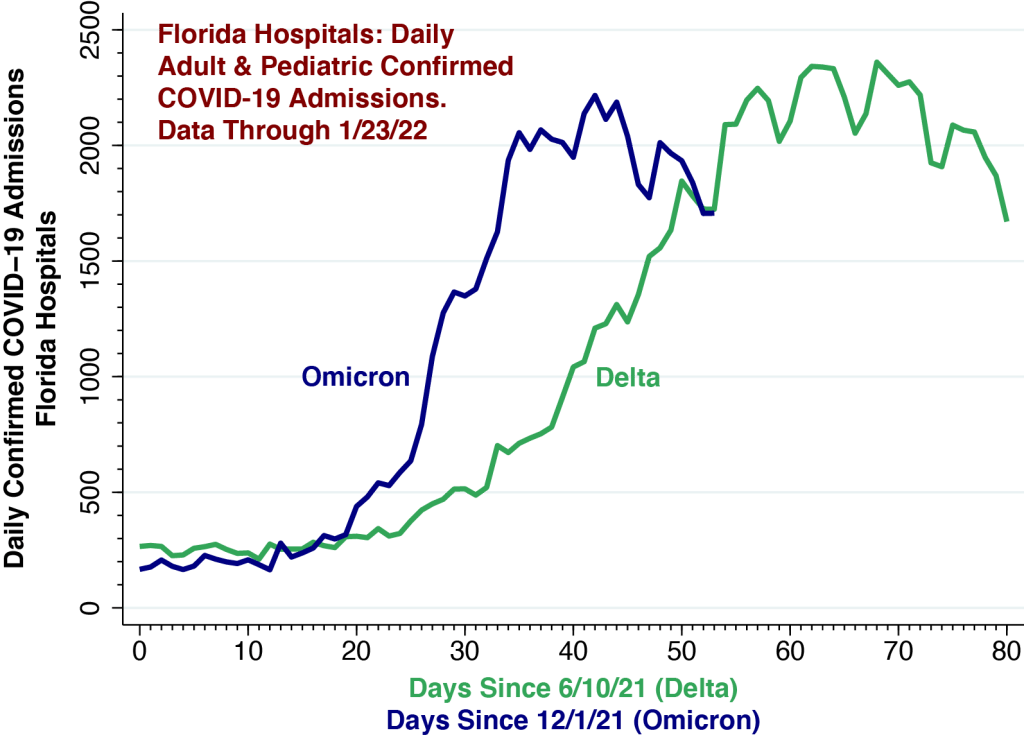
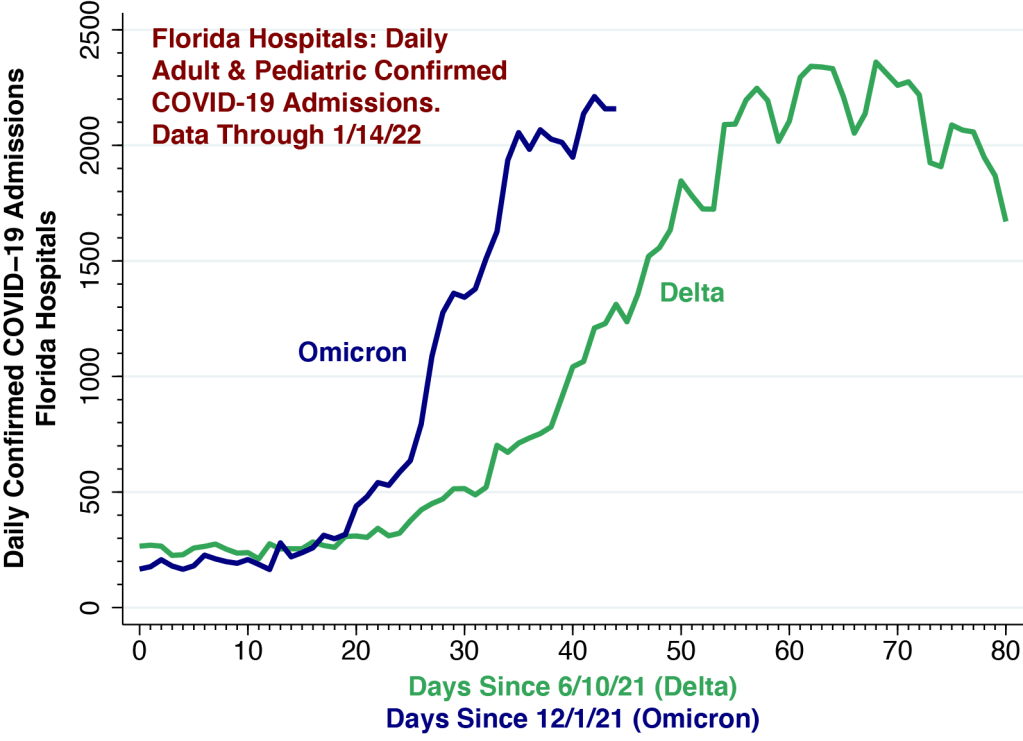
We used an established statistical method to “now-cast” cases that have already been diagnosed but have yet to be reported.
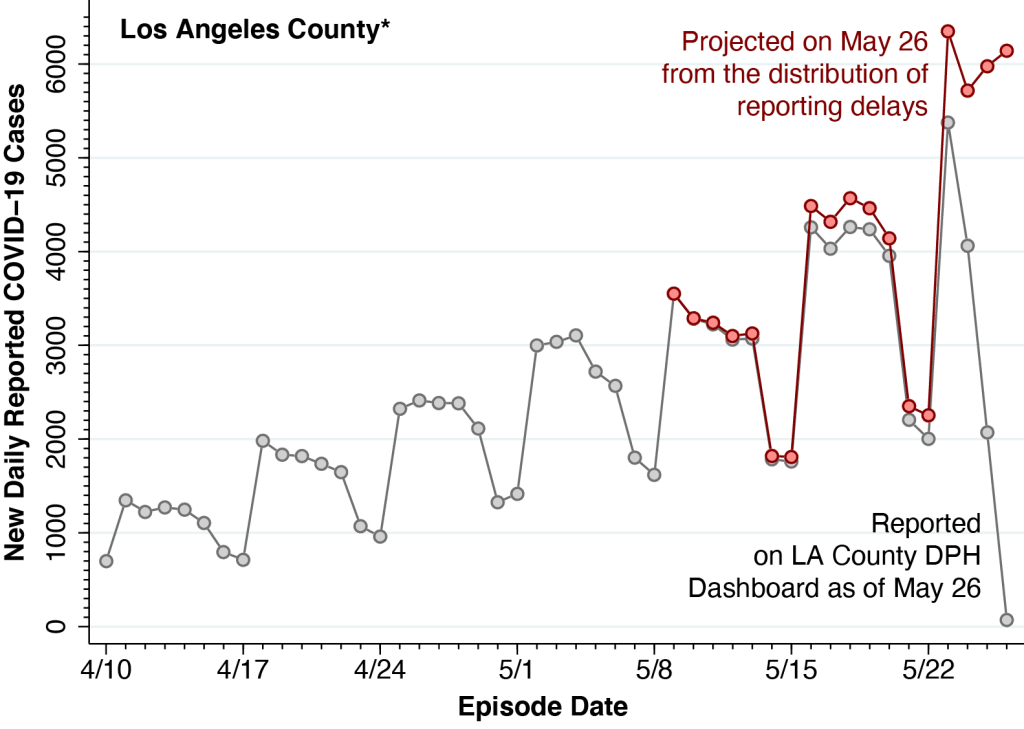
The gray data points in the figure show the numbers of daily reported COVID-19 cases in Los Angeles County, where the “episode date” essentially represents the date that each case was diagnosed. The number of cases trails off markedly during the most recent week as a result of delays in reporting. While the Department of Public Health acknowledges this data limitation, it has not taken advantage of established statistical methods to project the actual number of cases, based upon the distribution of reporting delays.
The pink data points in the figure show the case projections that the DPH has yet to include in its reports. These projections were based on a statistical method, vetted in the peer-reviewed scientific literature, which has already been applied to COVID-19 reporting delays in New York City and to AIDS reporting delays nationwide.
Date of Diagnosis versus Date of Report
The figure above was constructed from detailed tables posted on the DPH Dashboard. (See “Table: Cases/Death by Date” here.) In a separate press release, the DPH acknowledged that reports of 6,245 cases had been received on May 26. The gray data points in the figure, however, fall well below the 6,000 mark. How do we resolve the apparent contradiction?
DPH’s detailed tables classify each reported case according to the date of diagnosis. Although there can be a lag of 2 or more days between the moment of infection and the date of testing, such date-of-diagnosis-based reporting still gives a more accurate picture of COVID-19 trends. The Department’s press release, by contrast, tallies cases according to the date that the case was reported, even though nearly all such reported cases were diagnosed earlier. In fact, all but 79 of those 6,245 reported cases were diagnosed before May 26.
The tabulation in the press release, accordingly, is playing catch-up on past cases. But it is still not capturing cases that have already been diagnosed but have yet to be reported. In fact, by our estimates, about 13,200 cases were already diagnosed but yet to be reported during the 7 days from May 20-26. That’s the area between the pink and gray curves.
Under-reporting: What it means
It is widely acknowledged that reported COVID-19 cases now substantially understate actual incident cases, as many infections diagnosed by home rapid antigen tests go unreported and still other asymptomatic cases go unnoticed without any testing at all. However, there is every reason to believe that the actual incidence of COVID-19, including both reported and unreported cases, is following the same markedly upward trend seen in the figure.
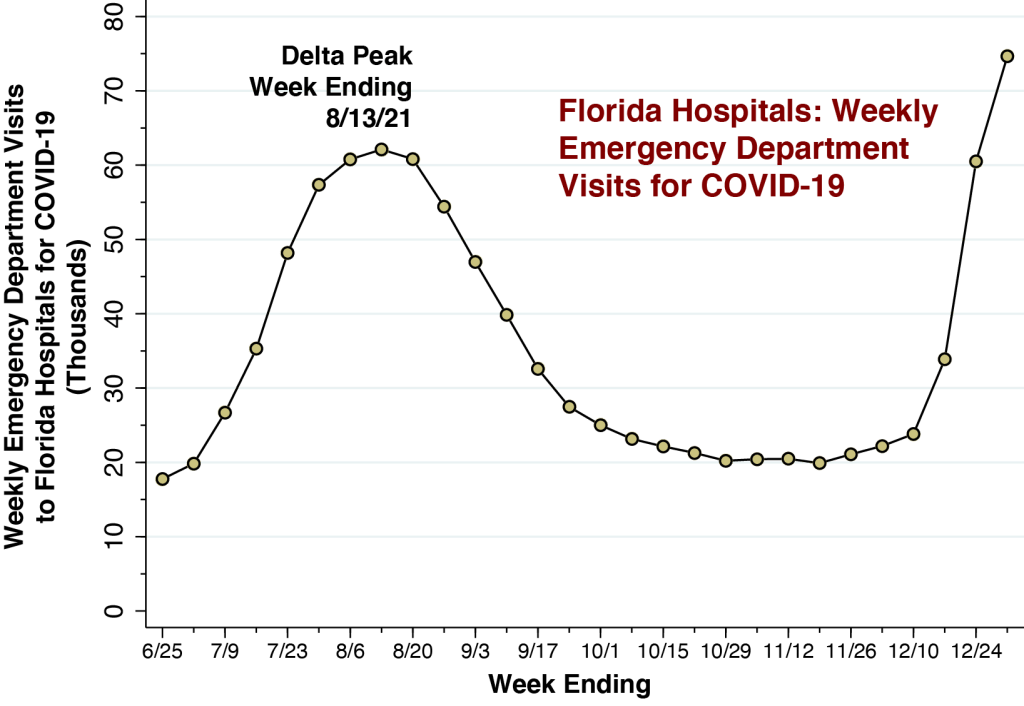
In fact, reported daily COVID-19 cases in Los Angeles County have already broken the 4,000-a-day peak seen during the Delta wave of July-August-2021, when under-reporting of cases was far less prevalent.
Cautions
The projections in the figure rely on the critical assumption that the estimated distribution of reporting delays remains stable. In particular, based on the timing of case reports during May 9 – 26, we have estimated that only about 1.2% of all cases were reported on the same day as they were diagnosed, while another 33.5% were reported with a one-day delay, another 36.4% were reported with a 2-day delay, another 13.6% reported with a 3-day delay, another 4.3% reported with a 4-day delay, after which the distribution of reporting delays exhibits a long tail up to 17 days.
Whether this estimated delay distribution continues to hold up during the long Memorial Day holiday weekend is hardly obvious. Our figure shows that Sundays have tended to be quiet days, while Mondays typically bring a spike in new diagnoses. But the Monday May 30 holiday may alter that pattern and thus extend the reporting delay.
On the other hand, the upcoming holiday weekend may have incentivized some symptomatic individuals to seek testing earlier on May 25 – 26, thus resulting in a one-time spike in diagnoses. In either case, we may need to wait more than a week or two before assessing whether the projections in the figure turn out to be accurate.
Technical Notes
All underlying data, programs and output have been posted on a public repository in the Open Science Framework.